My friends and I recently obtained a simple but surprising result on ARC AGI 2, getting > 4x performance improvement from GPT OSS 120B and double digit gains in GPT 5.2. Our team’s blog post describes the work in formal detail, while I will record our journey here.
My friends and I casually started working on ARC AGI 2 last summer, with the goal of participating in the ARC Prize Kaggle competition. Early on, we were exploring agentic coding with frontier reasoning models and found that models like o3 and o4-mini could generate high-quality synthetic ARC-style puzzles.
We generated a dataset containing ~ 8000 high-quality synthetic puzzles of varying complexity. Here are a few illustrative examples.
We planned to use these synthetic puzzles to train a smaller model via agentic reinforcement learning (RLVR with interleaved thinking).
We wanted to bootstrap training by distilling on successful solution traces from an open-weight reasoning model. That requirement led us to investigate GPT-OSS-120B. Initially, we were disappointed since we weren’t able to reliably elicit interleaved thinking from the model, no matter whether we used inference providers on Openrouter or self-hosted solutions like vLLM and SGLang. This led us on a journey of investigating how vLLM and SGLang implements the chat template for the model. We found that they are buggy, and patched vLLM to fix the bug.
At this point, we noticed something unexpected: simply placing the model into an agentic coding regime produced large and consistent score improvements on the ARC AGI public eval. We are talking about > 4x improvement relative to plain COT. We couldn’t believe the scores we were getting from a medium sized OSS model!
This observation ultimately shifted the focus of our work as we wanted to find out how universally this observation applies. We tested three model families and got positive results on all three. At this point, we decided to publish our results.
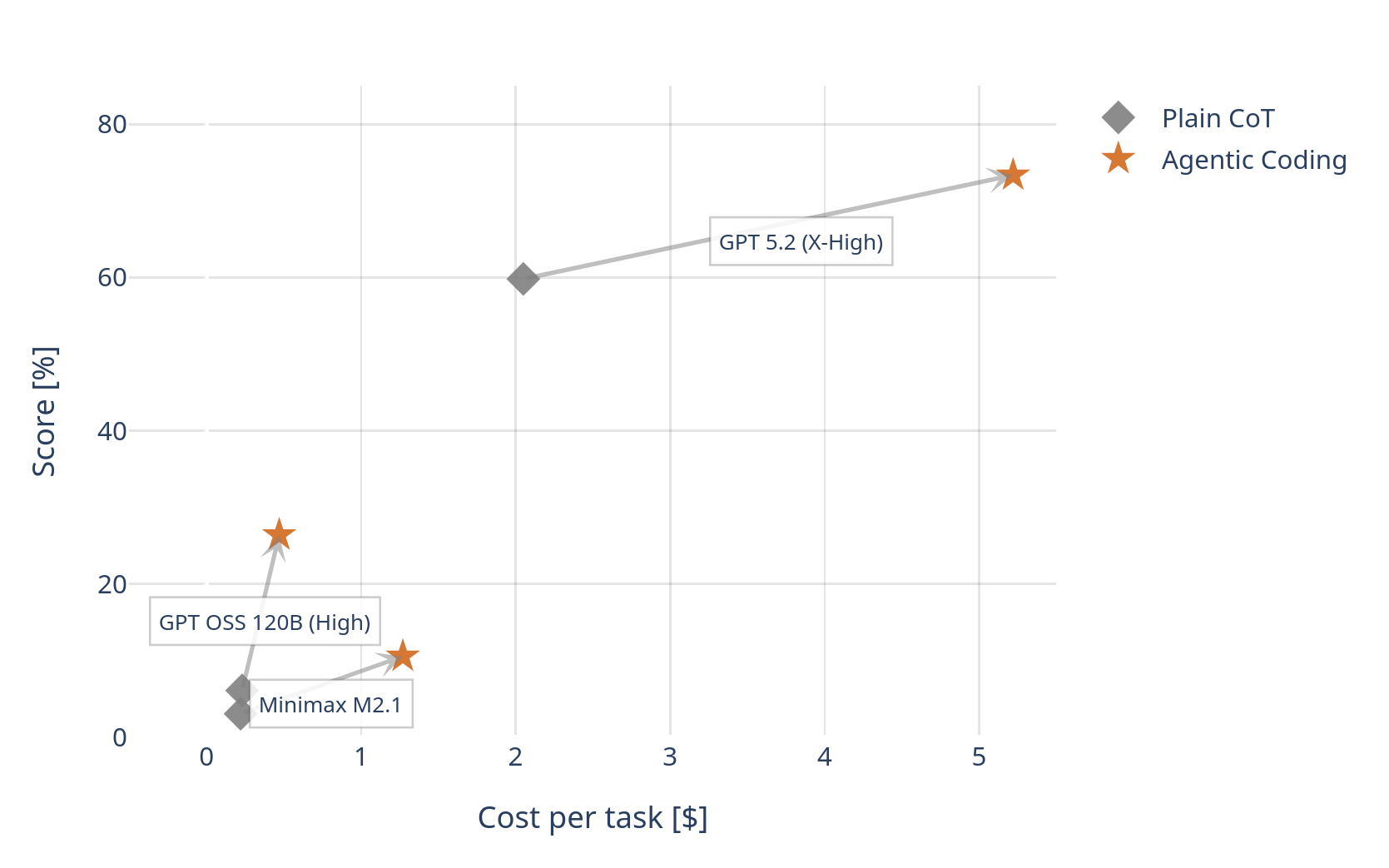
Shortly afterwards, a neolab called Symbolica announced SOTA applying the same method with the newly released Claude Opus 4.6. Here’s their post from X.
We set a new ARC-AGI-2 SotA: 85.28% using an Agentica agent (~350 lines) that writes and runs code. pic.twitter.com/tohFfBZb2P
— Agentica (@agenticasdk) February 12, 2026
A few weeks later, a YCombinator startup Confluence Labs saturated the ARC AGI 2 public eval (97.9%) using the same method with the newly released Gemini 3.1 Pro. Here’s their post from X.
.@_confluencelabs is coming out of stealth with SOTA on ARC-AGI-2 (97.9%).
— Y Combinator (@ycombinator) February 24, 2026
They're focused on learning efficiency — making AI useful where data is sparse and experiments are costly. Read more at https://t.co/K9NEFR6M0S
Congrats on the launch, @BingBongBrent and @bankminer78!… pic.twitter.com/4VjDyPNfvP
Other than clear implications on SOTA, I think this raises interesting scientific questions.
- All the 5 model families tested by our group, Symbolica and Confluence Labs had a significant agentic RL posttraining phase. Since our method performs inference under the exact same condition that was available during agentic RL training, does the capability jump indicate that agentic RL training induces additional fluid intelligence in models?
- There is a widespread belief that modern frontier models are trained on massive amounts of synthetic ARC AGI 2 like puzzles. This is termed “benchmaxxing” and many people argue that the performance increases observed in the leaderboard aren’t evidence of true fluid intelligence. Our results on open-weight models could provide a counterpoint. The plain COT performance of the open-weight models are at near noise levels (~ 5% on ARC AGI 2), effectively ruling out benchmaxxing. Interestingly, the performance of the same models jump significantly in the inference regime corresponding to agentic RL training. Could this be indicative of true increases in fluid intelligence?